 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlon Lavie
Dialogue Quality and Emotion Annotations for Customer Support Conversations
Nov 23, 2023
Task-oriented conversational datasets often lack topic variability and linguistic diversity. However, with the advent of Large Language Models (LLMs) pretrained on extensive, multilingual and diverse text data, these limitations seem overcome. Nevertheless, their generalisability to different languages and domains in dialogue applications remains uncertain without benchmarking datasets. This paper presents a holistic annotation approach for emotion and conversational quality in the context of bilingual customer support conversations. By performing annotations that take into consideration the complete instances that compose a conversation, one can form a broader perspective of the dialogue as a whole. Furthermore, it provides a unique and valuable resource for the development of text classification models. To this end, we present benchmarks for Emotion Recognition and Dialogue Quality Estimation and show that further research is needed to leverage these models in a production setting.
Simple LLM Prompting is State-of-the-Art for Robust and Multilingual Dialogue Evaluation
Sep 08, 2023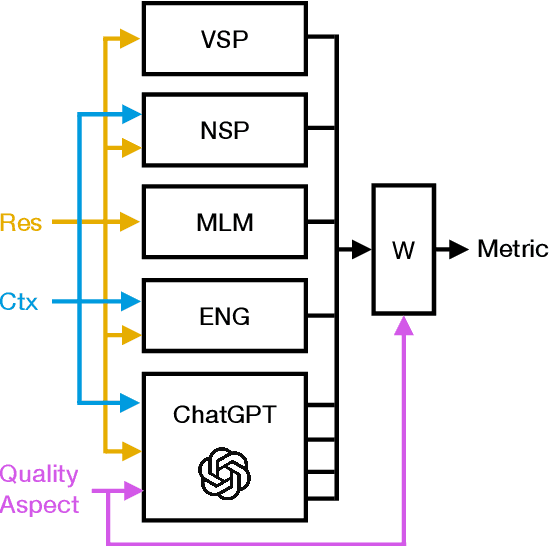
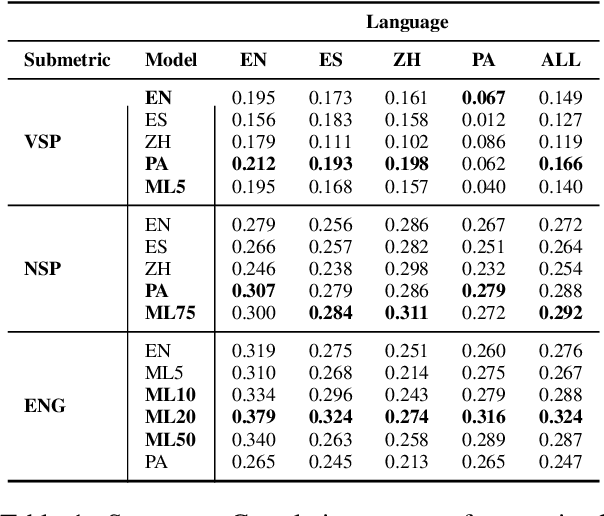

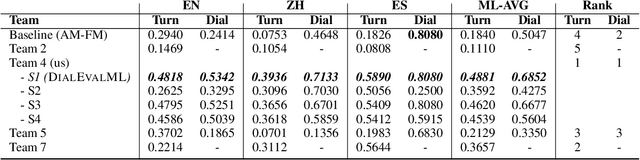
Despite significant research effort in the development of automatic dialogue evaluation metrics, little thought is given to evaluating dialogues other than in English. At the same time, ensuring metrics are invariant to semantically similar responses is also an overlooked topic. In order to achieve the desired properties of robustness and multilinguality for dialogue evaluation metrics, we propose a novel framework that takes advantage of the strengths of current evaluation models with the newly-established paradigm of prompting Large Language Models (LLMs). Empirical results show our framework achieves state of the art results in terms of mean Spearman correlation scores across several benchmarks and ranks first place on both the Robust and Multilingual tasks of the DSTC11 Track 4 "Automatic Evaluation Metrics for Open-Domain Dialogue Systems", proving the evaluation capabilities of prompted LLMs.
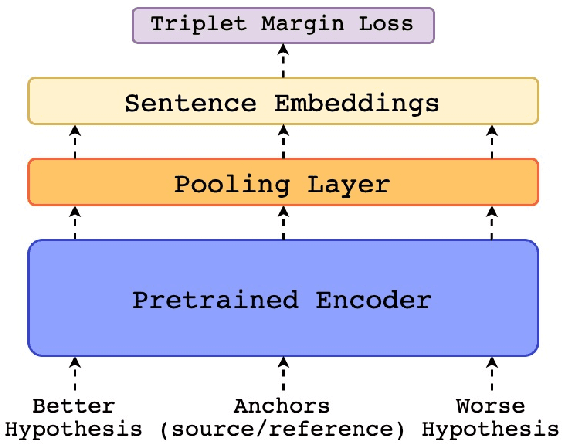
Towards Multilingual Automatic Dialogue Evaluation
Aug 31, 2023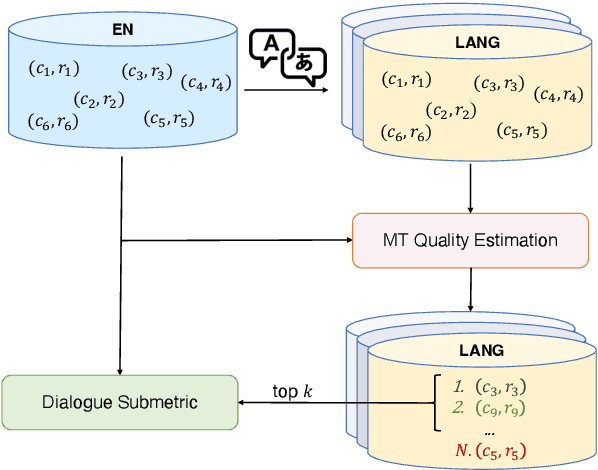


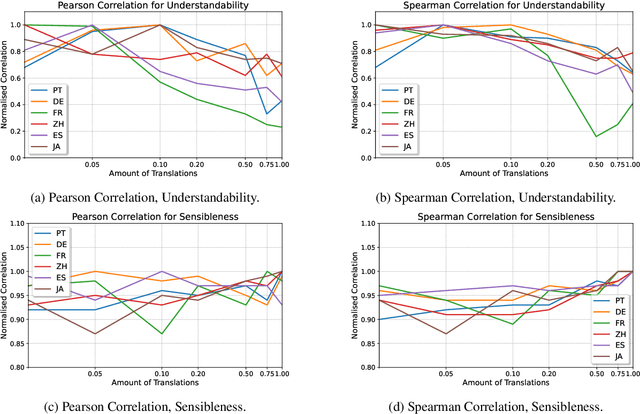
The main limiting factor in the development of robust multilingual dialogue evaluation metrics is the lack of multilingual data and the limited availability of open sourced multilingual dialogue systems. In this work, we propose a workaround for this lack of data by leveraging a strong multilingual pretrained LLM and augmenting existing English dialogue data using Machine Translation. We empirically show that the naive approach of finetuning a pretrained multilingual encoder model with translated data is insufficient to outperform the strong baseline of finetuning a multilingual model with only source data. Instead, the best approach consists in the careful curation of translated data using MT Quality Estimation metrics, excluding low quality translations that hinder its performance.
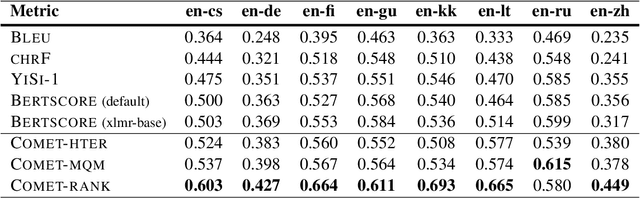
The Inside Story: Towards Better Understanding of Machine Translation Neural Evaluation Metrics
May 19, 2023
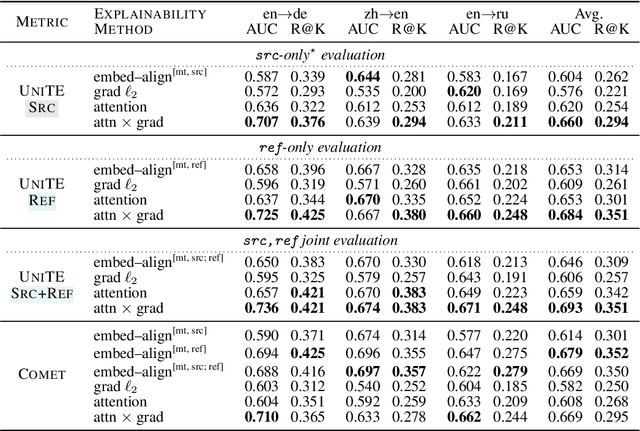
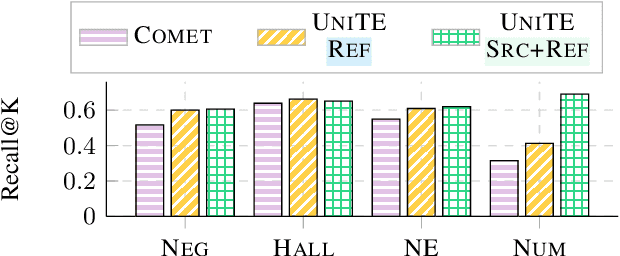
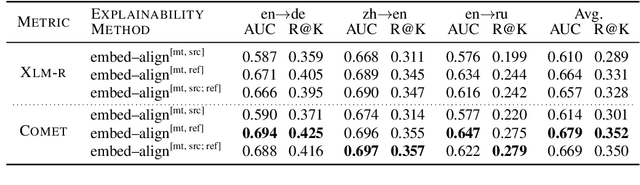
Neural metrics for machine translation evaluation, such as COMET, exhibit significant improvements in their correlation with human judgments, as compared to traditional metrics based on lexical overlap, such as BLEU. Yet, neural metrics are, to a great extent, "black boxes" returning a single sentence-level score without transparency about the decision-making process. In this work, we develop and compare several neural explainability methods and demonstrate their effectiveness for interpreting state-of-the-art fine-tuned neural metrics. Our study reveals that these metrics leverage token-level information that can be directly attributed to translation errors, as assessed through comparison of token-level neural saliency maps with Multidimensional Quality Metrics (MQM) annotations and with synthetically-generated critical translation errors. To ease future research, we release our code at: https://github.com/Unbabel/COMET/tree/explainable-metrics.
Appropriateness is all you need!
Apr 27, 2023The strive to make AI applications "safe" has led to the development of safety-measures as the main or even sole normative requirement of their permissible use. Similar can be attested to the latest version of chatbots, such as chatGPT. In this view, if they are "safe", they are supposed to be permissible to deploy. This approach, which we call "safety-normativity", is rather limited in solving the emerging issues that chatGPT and other chatbots have caused thus far. In answering this limitation, in this paper we argue for limiting chatbots in the range of topics they can chat about according to the normative concept of appropriateness. We argue that rather than looking for "safety" in a chatbot's utterances to determine what they may and may not say, we ought to assess those utterances according to three forms of appropriateness: technical-discursive, social, and moral. We then spell out what requirements for chatbots follow from these forms of appropriateness to avoid the limits of previous accounts: positionality, acceptability, and value alignment (PAVA). With these in mind, we may be able to determine what a chatbot may and may not say. Lastly, one initial suggestion is to use challenge sets, specifically designed for appropriateness, as a validation method.
CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task
Sep 13, 2022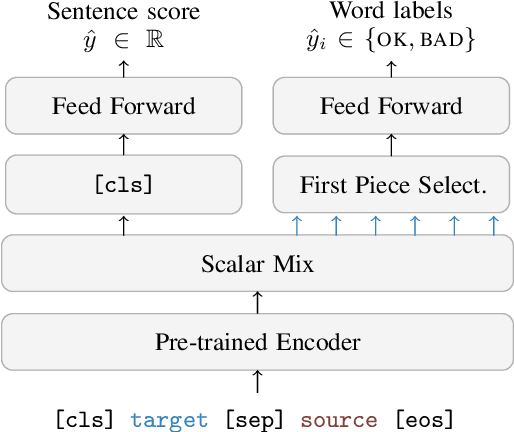
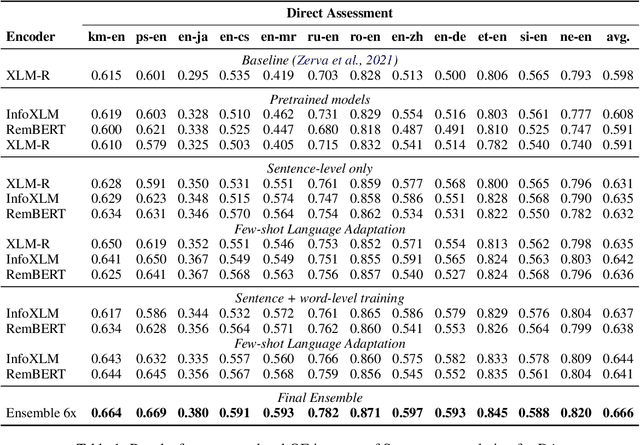
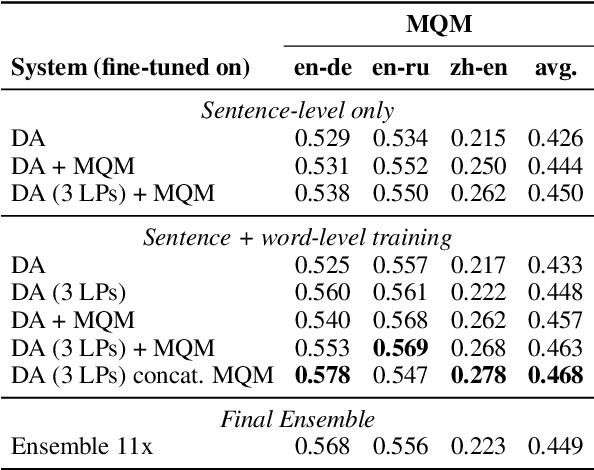
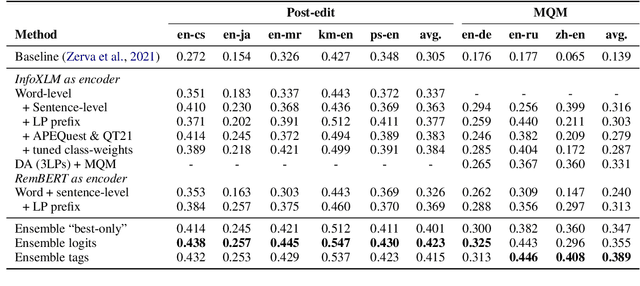
We present the joint contribution of IST and Unbabel to the WMT 2022 Shared Task on Quality Estimation (QE). Our team participated on all three subtasks: (i) Sentence and Word-level Quality Prediction; (ii) Explainable QE; and (iii) Critical Error Detection. For all tasks we build on top of the COMET framework, connecting it with the predictor-estimator architecture of OpenKiwi, and equipping it with a word-level sequence tagger and an explanation extractor. Our results suggest that incorporating references during pretraining improves performance across several language pairs on downstream tasks, and that jointly training with sentence and word-level objectives yields a further boost. Furthermore, combining attention and gradient information proved to be the top strategy for extracting good explanations of sentence-level QE models. Overall, our submissions achieved the best results for all three tasks for almost all language pairs by a considerable margin.
Unbabel's Participation in the WMT20 Metrics Shared Task
Oct 29, 2020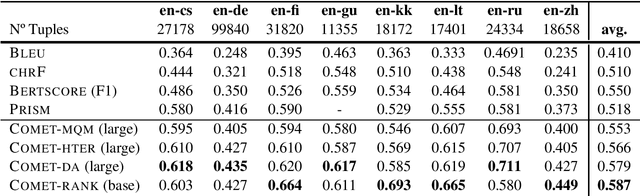
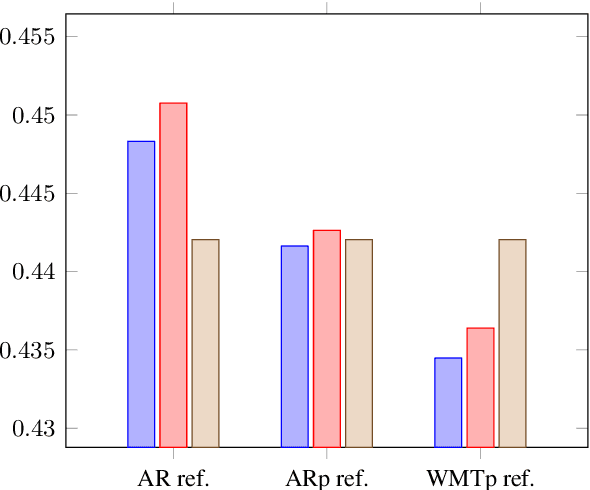
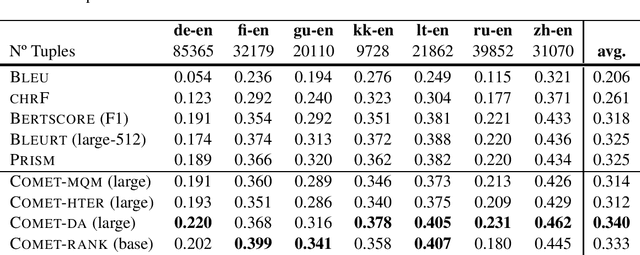
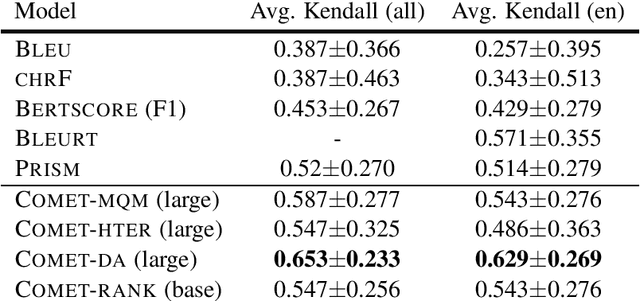
We present the contribution of the Unbabel team to the WMT 2020 Shared Task on Metrics. We intend to participate on the segment-level, document-level and system-level tracks on all language pairs, as well as the 'QE as a Metric' track. Accordingly, we illustrate results of our models in these tracks with reference to test sets from the previous year. Our submissions build upon the recently proposed COMET framework: We train several estimator models to regress on different human-generated quality scores and a novel ranking model trained on relative ranks obtained from Direct Assessments. We also propose a simple technique for converting segment-level predictions into a document-level score. Overall, our systems achieve strong results for all language pairs on previous test sets and in many cases set a new state-of-the-art.
COMET: A Neural Framework for MT Evaluation
Oct 19, 2020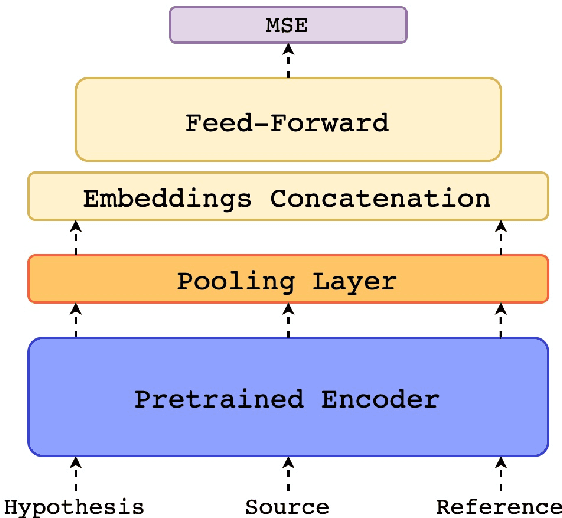

We present COMET, a neural framework for training multilingual machine translation evaluation models which obtains new state-of-the-art levels of correlation with human judgements. Our framework leverages recent breakthroughs in cross-lingual pretrained language modeling resulting in highly multilingual and adaptable MT evaluation models that exploit information from both the source input and a target-language reference translation in order to more accurately predict MT quality. To showcase our framework, we train three models with different types of human judgements: Direct Assessments, Human-mediated Translation Edit Rate and Multidimensional Quality Metrics. Our models achieve new state-of-the-art performance on the WMT 2019 Metrics shared task and demonstrate robustness to high-performing systems.
An Efficient Distribution of Labor in a Two Stage Robust Interpretation Process
Jun 17, 1997
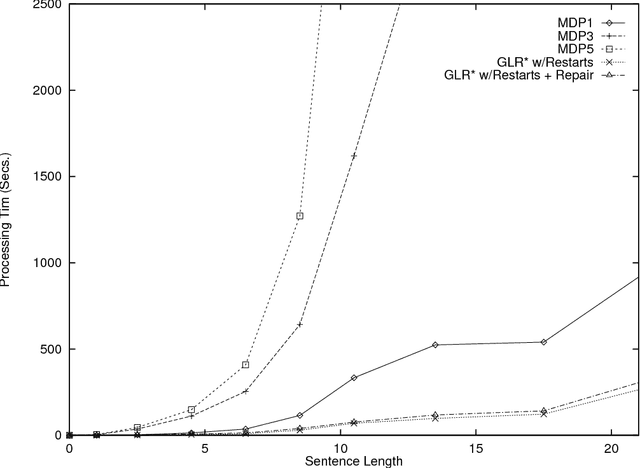
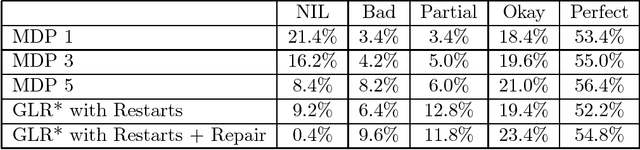
Although Minimum Distance Parsing (MDP) offers a theoretically attractive solution to the problem of extragrammaticality, it is often computationally infeasible in large scale practical applications. In this paper we present an alternative approach where the labor is distributed between a more restrictive partial parser and a repair module. Though two stage approaches have grown in popularity in recent years because of their efficiency, they have done so at the cost of requiring hand coded repair heuristics. In contrast, our two stage approach does not require any hand coded knowledge sources dedicated to repair, thus making it possible to achieve a similar run time advantage over MDP without losing the quality of domain independence.
An Integrated Heuristic Scheme for Partial Parse Evaluation
May 26, 1994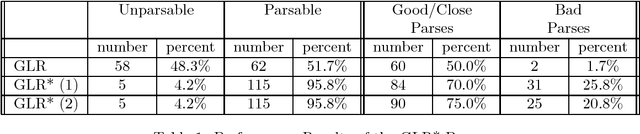
GLR* is a recently developed robust version of the Generalized LR Parser, that can parse almost ANY input sentence by ignoring unrecognizable parts of the sentence. On a given input sentence, the parser returns a collection of parses that correspond to maximal, or close to maximal, parsable subsets of the original input. This paper describes recent work on developing an integrated heuristic scheme for selecting the parse that is deemed ``best'' from such a collection. We describe the heuristic measures used and their combination scheme. Preliminary results from experiments conducted on parsing speech recognized spontaneous speech are also reported.
* 3 pages, 1 table, LaTeX source, uses latex-acl.sty and named.sty To appear in proceedings of ACL-94 (student sessions)